
Newsletter #12: System Design for Machine Learning - Part II
Exploring case studies to see how frameworks are applied in production

In the last post, we explored the basic principles that can be used while designing a Machine Learning System. In this post, let’s look at a couple of case studies and how they applied these principles.

Case Study 1: Predicting LTV at Airbnb
LTV stands for Customer Lifetime Value, meaning the amount of money a customer will spend once he signs up. Usually, this value is determined using historical data, but Airbnb took it a step further and built a model to predict the LTV of new listings.
Feature engineering
Airbnb used their internal tool Zipline, which allows the user to select features vetted on past projects. If a feature is unavailable, the user can create a new feature that is added to Zipline for further use. A configuration file is used to specify which features are to be picked up from the data. The LTV model had over 150 features!
Prototyping and Model Training
Rapid prototyping is essential when you have many features to choose from and many models that can be used for prediction. For feature selection, they used the pipelines available in Scikit-Learn. Here is a simple code given by the author:
transforms = []
transforms.append(
('select_binary', ColumnSelector(features=binary))
)
transforms.append(
('numeric', ExtendedPipeline([
('select', ColumnSelector(features=numeric)),
('impute', Imputer(missing_values='NaN', strategy='mean', axis=0)),
]))
)
for field in categorical:
transforms.append(
(field, ExtendedPipeline([
('select', ColumnSelector(features=[field])),
('encode', OrdinalEncoder(min_support=10))
])
)
)
features = FeatureUnion(transforms)Using this pipeline as well as estimators, models can be trained quickly and iteratively.
Deployment
Airbnb uses a framework called AirFlow that automates the process of deployment. The design is as follows:
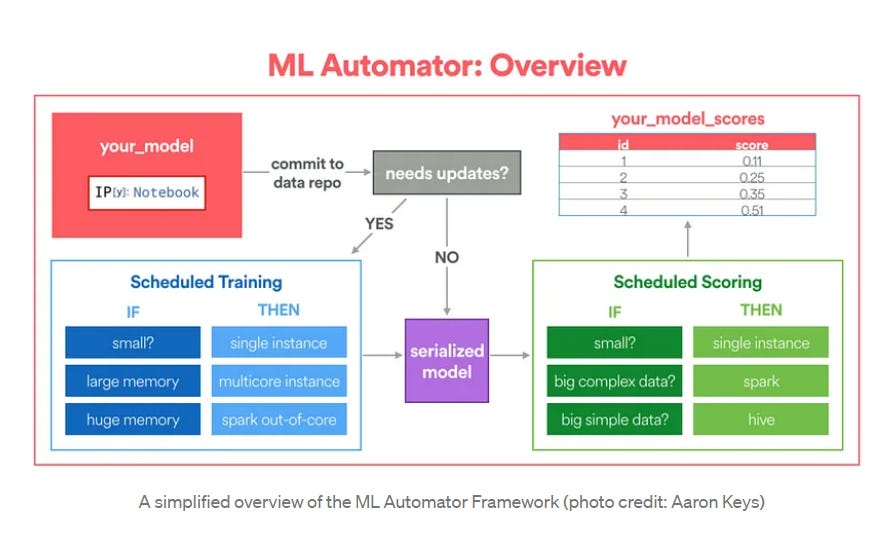
The framework needs two inputs:
Model Config: Tells the location of training data, how to compute scores and how many resources to allocate.
Fit and transform functions: They specify how to train the model and score the model respectively.
As we see the process follows a similar flow as described in the last post. Now let’s take a look at another case study, of Chicisimo.
Case Study 2: Using ML to Boost the fashion advice
Chicisimo’s goal was to use ML to learn the user’s fashion preferences and give them advice just like a friend would. Let’s look at how they set up their system.

Data Gathering
Chicisimo used the data provided by their users to build and update their dataset. This included objective features such as size, price, colour, type, etc as well as subjective features such as styles, occasions, etc.
They built a Social Fashion Graph to make the data actionable. This graph connected outfits, needs and people to each other. They thought of outfits as a playlist of various single items.
Since people can describe a similar outfit in various ways, they also build another tool called fashion ontology which is a multi-level descriptor of outfits or an n-ary tree.
Model Building
Chicisimo built a recommendation system on top of the fashion ontology tool. It allowed them to use the descriptors as meta-products and club similar products together. This solved the problem of the confusion caused by different product descriptions for the same product.
Conclusion
Case studies are an effective way to learn about how frameworks are applied in production. There are always a few changes required due to the specific requirements of a project. Hence I feel you need both, a framework to guide you when you start a new project and enough knowledge from case studies to understand that no framework will give you the full solution, but only a helping hand.
That’s it for this issue. I hope you found this article interesting. Until next time!
📖Resources
Let’s connect :)
