
Newsletter #14: Adding Memory to LLMs
How to make LLMs remember stuff

In the paper, ‘’Think Before You Act: Decision Transformers with Internal Working Memory”, by Jikun et. al., a new framework called Decision Transformers with Memory (DT-Mem) is proposed in order to improve the ability of LLMs to work better on generalization tasks. LLMs have implicit memory and can be used in novel ways to build something that mimics the human brain as we saw in this post.

However, as the size of the LLMs grows, the LLM tends to “forget” some things resulting in poor results. Hence, the authors propose an internal memory module to improve LLMs' generalizations and adaptability.
Let’s take a look at how DT-Mem works.
Model Setup

The problem is formulated as a Markov Decision Process (MDP). This means for every state transition Sn → Sn+1, the inputs as well as some x previous states are taken into consideration.
The MDP tuple consists of the following elements:
S - Set of states
A - Set of Actions
R - Reward Function
p - Transition Kernel (More on this below)
γ - Discount Factor
The transition kernel p is defined as S1 * A * S2 → (0, 1) which can be thought of as the probability of reaching state S2 from S1 by taking action A.
LoRA
A second essential component is LoRA or the Low-Rank Adaption method. This is used to map old knowledge to new tasks. The idea behind LoRA is to learn a low-rank matrix for a new task and then use it to get the relevant subspace from the old task.
An intuitive way to think about this is using the vector space of the old tasks, which is large, and extracting only the parts relevant to the current tasks from that space.
Architecture
DT-Mem consists of three components: the Transformer module, the Memory module, and the Multi-layer perceptron (MLP) module.

Transformer Module
It takes in a sequence of n tokens and gives the output as one of attended state embeddings, action embeddings, or return-to-go embeddings.
Working Memory Module
This module is based on the adage “Think before you act” and works by identifying the salient information, deciding where to store the information and how to integrate the new memory with the current memory state.
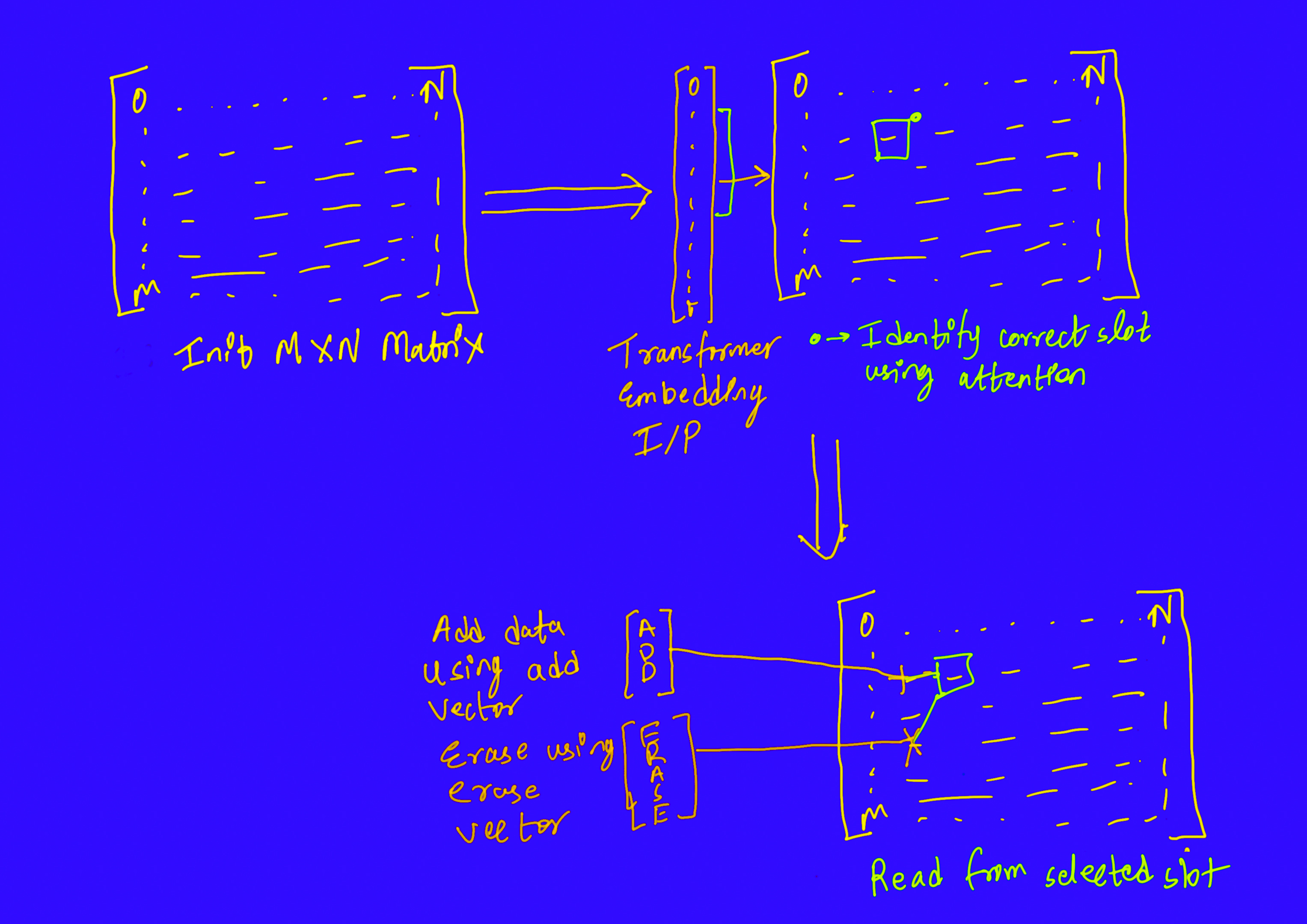
The memory is initialized as a random M*N matrix where each location (i, j) represents a slot.
Then using content-based addressing that uses the attention mechanism, the right slot to store the memory is identified. The intuition behind this is that we store similar information together.
To merge the new memory with the current state, two new vectors are used, the erasing vector and the addition vector. The erasing vector selectively removes information from the memory matrix and the addition vector selectively adds new information.
To retrieve the information, the same attention mechanism is used to identify the slot most relevant to the query and then read from that slot.
MLP
The multi-layer perception module is similar to the GPT-2 model, only it is decoupled from the transformer module and has the memory model preceding it. It produces the final result by taking the combined embedding from the transformer and memory modules.
Conclusion
This model was able to work well in Atari and Meta-world environments. Using just the weights of the neural network poses challenges that are solved by having a memory module.
Such new and innovative ideas are coming up every week. It feels like an inflexion point and maybe a major breakthrough that will vastly improve LLMs’ ability to solve general tasks is right on the horizon. These are exciting days in the world of AI!
That’s it for this issue. I hope you found this article interesting. Until next time!
📖Resources
Let’s connect :)
