
Newsletter 21: To keepdims or not to keepdims!
A note about broadcasting rules in Pytorch

Hi Everyone! It's been a long time since I wrote a post, if you are still subscribed, thank you! :)
So I am working through Andrej Karpathy’s makemore series to understand better how different ML models work. In his bi-gram model video, he talks about the keepdims parameter in the tensor.sum function and how understanding it is important. So I thought I’d write a post (mostly for myself), so I can come back and revise what I have learnt.
Let’s start with the basics:
The 2 conditions for tensors to be broadcastable is
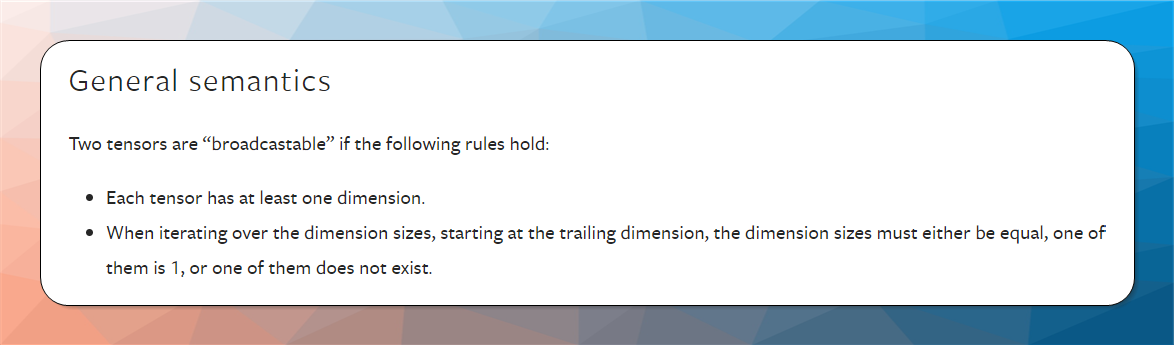
The official documentation has many examples, but I will just use the example from the tutorial.
In the bi-gram model, the first step is to create a n*n character array that stores the frequency of each pair or bi-grams. For example row[1][1] stores how frequently the bi-gram ‘aa’ appeared in the dataset. Additionally, we also add a ‘.’ symbol to denote the start and end of every sequence hence we get a 27*27 array, with row 0 being the special symbol ‘.’ and rows 1 to 27 being characters a-z. Any position [i][j] holds how many times character j followed character i.
Now the way we build the model is to sample from a multinomial probability distribution of these counts. To do that we first need to convert the raw counts to probabilities that sum up to 1. To do this, we use the following code:

The generator is just to get consistent results.
P is a tensor that stores the counts (stored in N as ints) as floats.
Then we sum along the columns and set keepdim to be True.
The result is a tensor of size [27, 1]
Now according to the rules, tensors of size 27*27 and 27*1 are broadcastable if from the right, each pair is either 1, equal or non existent.
Pair 1, 27 → One of them is 1
Pair 27, 27 → Equal
Internally, Pytorch copies the column vector 27 times and does element-by-element division.
Now to the problem,
If keepdims is false, we get a tensor of size [27]. If we check [27, 27] and [27, ] are broadcastable, they are since in the first pair, one of dims is non-existent and hence allowed. So the code runs without errors, however, the output produced is complete garbage. See the example below:


These are supposed to be names! Granted that the bi-gram model is pretty poor at estimating names, but the first image has at least lengths that somewhat resemble names with keepdims = False, it is producing sentences!
So what is happening here?

Look at the image above, in the first case, we have the shape (27,1) hence we sum across columns and then get a column vector which is copied 27 times across. However, when we implicitly get (1,27) due to missing dimensions, we sum across rows and get a row vector which is copied horizontally 27 times.
Hence in case 1, we correctly divide the count of say ‘.b’ with the sum of all instances where the the prefix is ‘.’ , But in the second case, we divide with instances where b followed some letter, which is incorrect!
This can be a tricky bug given that neural nets and ml models can produce incorrect results for myriad of reasons and hence when you have a complex model, it’s easy to miss this simple reason.
I would love to read any more tutorials you might come across, feel free to send them to me!
I hope you found this article useful. Until next time!
📖Resources
Let’s connect :)
