


Newsletter #15: ViperGPT
Answering user queries about images using LLM and Python

A lot of different tools are released every week that leverage fine-tuned LLMs. In last few weeks, we saw models such as HuggingGPT, which uses LLMs to plan complex tasks, StructGPT, which uses iterative read-then-reason approach to find insights from structured data, DT-Mem which adds a memory module to the LLM to better model the human brain, etc.
In line with these advances, ViperGPT is a new LLM based model that uses LLMs as well as some vision models such as GLIP, MiDaS, X-VLM in conjunction with Codex to create a model capable of answering questions based on images and videos.

The use of LLMs to generate code and pre-trained models to make the code generation fast and efficient makes this model interesting.
Let’s take a look at how ViperGPT works.
Design
The input to the program is a visual input (image/video) and a user query related to the visual input.
The first step is to generate a program using the query q,
z = ⫪(q), where ⫪ is the program generator
Then using the program z, and the visual input v, we get the result r.
r = Ø(x, v), where Ø is the execution engine.
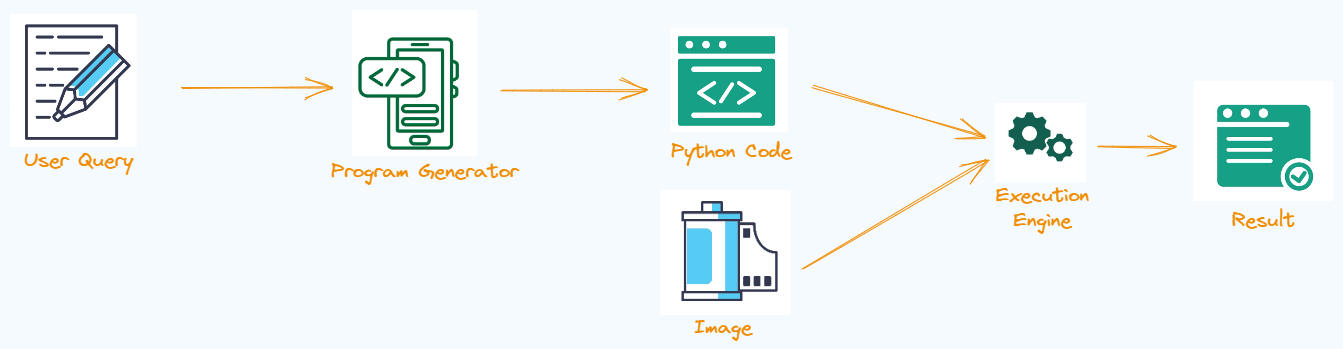
The program z is generated in Python using OpenAI Codex API to allow flexibility as well as programming tools such as loops and conditional statements.
Implementation
Not that we’ve seen the high level design, let’s look at how each of the components work, starting with the program generator ⫪.
Program Generator ⫪
In previous approaches, ⫪ was generated using a neural network. However this has certain drawbacks such as
At scale, supervised learning is not efficient due lack of available data.
The computation costs also grow with size.
ViperGPT uses LLMs to autoregressively* generate code based on the user query. Since the optimization is done using LLMs, all the python code available on the internet can be used for fine-tuning, hence removing the issue of scale in traditional approaches.
*Autoregressive prediction - Predict token at time T based on a few token x before time T i.e. for computing T use tokens T-1, T-2, ….., T-x.
The input to the LLM is the API specification of certain pre-trained models along with the user-query. Since the exact implementation is not provided it allows for greater flexibility in the output.
For example:
def find(self, object_name: str) -> List[ImagePatch]:
"""Returns a list of ImagePatch objects matching object_name contained in the crop if any are found.
Otherwise, returns an empty list.
Parameters
----------
object_name : str
the name of the object to be found
Returns
-------
List[ImagePatch]
a list of ImagePatch objects matching object_name contained in the crop
Examples
--------
>>> # return the children
>>> def execute_command(image) -> List[ImagePatch]:
>>> image_patch = ImagePatch(image)
>>> children = image_patch.find("child")
>>> return children
"""
Example API Spec input to the LLMLet’s look at an example from the paper for the task of Visual Grounding, which means to find out spatial relationships and visual attributes of an image. Following APIs of the pre-trained model are given as input to ViperGPT: (model names are in parenthesis)
find (GLIP): takes as input an image and a short noun phrase (e.g. “car” or “golden retriever”), and returns a list of image patches containing the noun phrase.
exists (GLIP): takes as input an image and a short noun phrase and returns a boolean indicating whether an instance of that noun phrase is present in the image.
verify_property (XVLM): takes as input an image, a noun phase representing an object, and an attribute representing a property of that object; it returns a boolean indicating whether the property is present in the image.
best_image_match (X-VLM) takes as input a list of image patches and a short noun phrase, and returns the image patch that best matches the noun phrase
best_text_match(X-VLM): takes as input a list of noun phrases and one image, and returns the noun phrase that best matches the image.
compute_depth (MiDaS) computes the median depth of the image patch.

Using these methods of pre-trained models as well as the user query, the code z can be generated. Now let’s look at the execution engine Ø
Execution Engine Ø
At execution time, the generated program z accepts an image or video as input and outputs a result r corresponding to the query provided to the LLM.
The execution engine uses a Python interpreter to run the code generated by the program generator. This allows it to use built-in functions and tools such as sort, if/else, loops, etc.
You can see the full code here, but here is how the code is executed using python’s exec() function:
"""
exec is used to interpret a string as python code
"""
exec(compile(code_line, 'Codex', 'exec'), globals())
result = execute_command(im, my_fig, time_wait_between_lines, syntax) # The code is created in the exec()
Examples:
Here are a couple example of ViperGPT in action:

LLMs are helping to build tools that help to give better explanations about raw data. ViperGPT is one of the first tools that can generate python code to preprocess data and use the results in conjunction with LLMs to add better context to the code execution results. I sure had fun reading this paper.
Let me know your thoughts.
That’s it for this issue. I hope you found this article interesting. Until next time!
📖Resources
IMG1 was made using Vector stock images, below are the attributions as per free license:
https://www.vectorstock.com/royalty-free-vector/random-icons-set-vector-7991904
https://www.vectorstock.com/royalty-free-vector/25-engine-icons-vector-36780597
https://www.vectorstock.com/royalty-free-vector/site-icons-vector-45958151
href="https://www.vectorstock.com/royalty-free-vector/form-icons-vector-45958593"
Let’s connect :)
